


We are a group of entrepreneurs that bring a wealth of experience and desires to build unique solutions that solve real world problems. The core team members each has decades of experience in developing new technologies, successfully bringing products to market, and growing an idea into a company. We have unique backgrounds from developing different cryptosystems for the U. S. National Security Agency, engineering FEDSTD-1026/1027 (now FIPS-140) test procedures for the DES-based cryptosystems, designing secured military field communication platforms for DARPA, building multi-core multi-threading network and communication processors with security accelerators, creating largescale telephony security endpoint validators, architecting security solutions for smart cards and DRM video distribution technologies, building the industry’s first enterprise class PCI-Express flash drive, to coding key enabling technologies for creating dynamic, automated, and self- optimizing data centers. Together, we strive to solve the challenges of data security.

Data Breach, a phrase that continues to impact every person in more ways than can be imagined. Billions of Personally Identifiable Information (PII) and Protected Health Information (PHI) records are stolen, held hostage, extorted, and resold every day. And it is getting worse thanks to unscrupulous platform tools, like Ransomware as a Service. From 2013 to 2019 approximately 25 billion records were pilfered by the darkest actors on the internet. Even with the advances in intrusion detection and protection, insight from machine learning, and well-defined access controls, some have estimated an average of four breaches occur a day equaling approximately six million records. So, we had to ask ourselves why with all the investments in new perimeter security products, new levels of prevention and awareness are records so easily taken by cybercriminals? Human factor is considered the most common denominator due to credential theft and social attacks. However, we see the real problem is the fact that once past any perimeter security infrastructure tasked with guarding the enterprise, the database holding the data is simply queried in the clear. Its literally that simple. Our vision is to protect the data itself. Customer and Client data, for example is encrypted and stored in a database, and remains encrypted until it needs to be displayed for the user. The industry is already encrypting data when it is stored, or at-rest, or when it is in-transit to the requester. Clearly, these latter approaches are not working – who steals a hard disk these days (?) and using SSL/TLS to protect the data in-transit is nifty, but the data is unprotected once it leaves the SSL/TLS tunnel. However, by Bonafeyed keeping all data encrypted, cybercriminals can only retrieve unintelligible bits, effectively rendering the data useless and demonetized. Our goal is to protect data no matter how it is used, who has it, or where it is located and even if the data is not well guarded.

Many have asked, how is Bonafeyed different from the various security technologies in the market today? The answer speaks to our approach and philosophy: “Protect the data don’t just guard it”. The two sound the same but they have vastly different meanings to us. If a solution requires the data to remain in a single domain (network) then more than likely it is based on an approach that controls access to the system in which it resides. For example, looking at a database, access or permission to a database management system determines who can query the data and in theory everything that is available for a specified group. You can see that this is simply a security perimeter or fence such as a firewall, an access portal, or a data loss prevention system. If you find a hole or flaw in the fence, you have visibility and access to the data within the perimeter. If the data is not encrypted, it is exposed. Now consider what happens when the data is shared outside the security “fence”? For example, data that is queried from a database. Technologies such as SSL/TLS and TDE can’t help. Once the data leaves the database and is sent to an endpoint device through maybe a web server, all data security is lost. In other words, the data was guarded but as soon as it leaves the premises (or cloud), there is nothing to safeguard it. When forwarding data to another domain, you hope that the recipient will protect and safeguard the data, but you have no assurances. These real-world scenarios drive how we think about data protection. Our view is to always protect the data no matter where it resides and ensure it stays protected (encrypted), even as the data moves across networks and domains, until such time it is decrypted for an authorized user.

There is an opening scene in Independence Day where Will Smith and Harry Connick Jr. lead an intrepid band of resolute jet pilots on a mission to attack one huge mother of an alien spacecraft. “They must have some kind of protective shield”, Will Smith exclaimed as they watch their sidewinder missiles explode harmlessly in the air. The realization is that this is how most cybersecurity technology operates -- a sophisticated perimeter that attempts to guard or keep attackers out while everything on the inside remains safe and sound.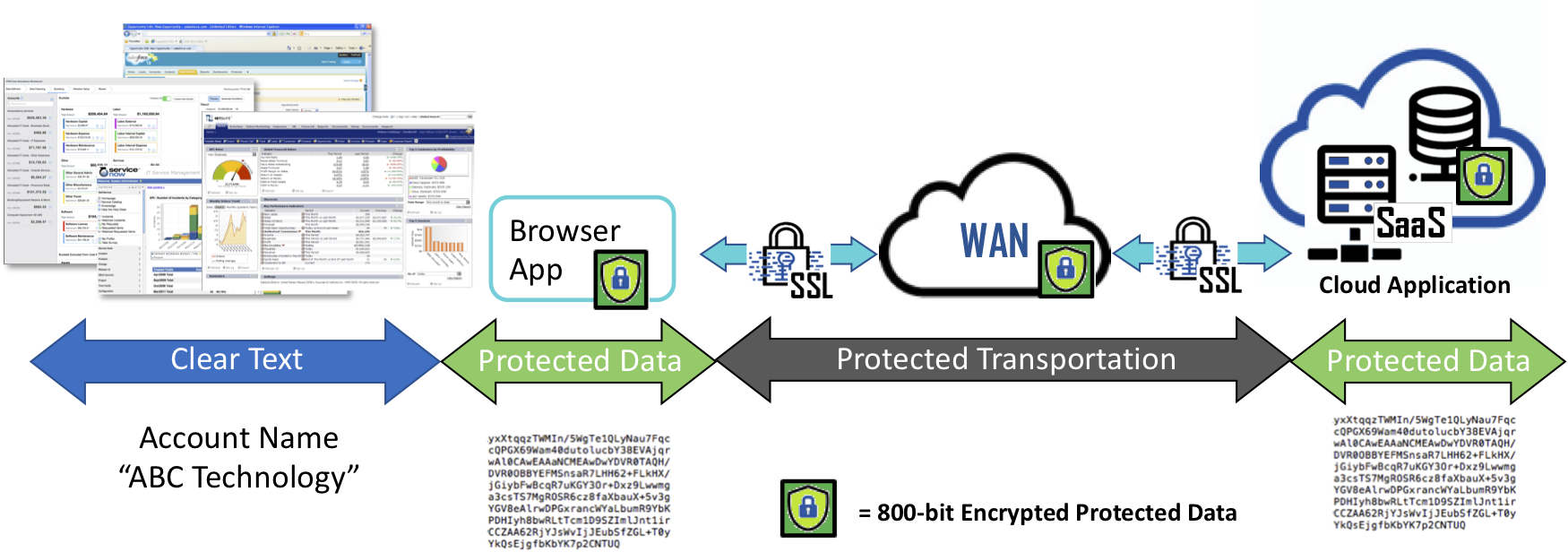
This method has been effective for a long time because the perimeter is a well-defined and understood boundary. But with the addition of BYOD, IoT, smartphones and cloud services, all of that has changed because the perimeter is no longer fixed. The way we view security needs to change, as sufficiently fortifying the perimeter is not only impossible, but most feel it is no longer worth the effort.
Today, the emphasis on data protection must shift from a perimeter-based solution to a data-defined approach because there are too many user access-points, and too much data to manage. Protecting individual data elements, PII and PHI, while seemingly unfeasible for most companies to consider, has never been more necessary.
According to Accenture and Ponemon Institute’s Cost of Cybercrime Study, breaches are growing by 27.4 percent per year even with the cost of cyber security growing by almost the same rate. Recent Gartner research states that enterprises and governments failed to protect approximately 75 percent of sensitive data in 2020. The 2019 Thales Data Threat Report revealed approximately 6 million records succumb to data breaches worldwide daily. Throwing money at trying to fortify the perimeter is no longer (although it never has been) 100 percent effective.
While we have already mentioned two facets of data security that must change - the first being moving from a systems approach to a data-defined approach, and the second being the need to acknowledge that the perimeter remains vulnerable as evident of the ongoing mega breaches, there is a third condition that needs adoption, and that is the necessity to move from manual human interactions to active, automated, authorizations and protection.
To illustrate the difference between manual implementation and active authorizations, let’s use Public Key Encryption (PKE) as an example. Public Key models work for the occasional message if the user is willing to do the prep work themselves. The users must exchange Public Keys with the intended recipients and do it in a way that they are confident as to the owner of the corresponding Private Key. And while this does work, at its core, it is a manual process which opens PKE to lack of adoption. When humans are involved, procedures will be forgotten or implemented incorrectly at some point.
Some may be thinking, “I am already doing data level encryption with application-layer encryption or per application file passwording”, but this is not at the data element level, it is at the file level. File level protection has one main weakness, it requires exposing the password to share files, and as the hierarchical complexity increases, (as more people or groups are added) users may stop using encryption, reuse existing passwords, or create common passwords to speed up the process.
At this point you may be feeling that data level protection may seem too complex, time consuming, or expensive to implement. Or you may be in the camp who is "hoping" data-at-rest encryption or transport protection (SSL or TLS) is good enough for data protection. However, anytime data is shared, when it leaves your domain and is placed or sent to another, that data is no longer protected. The right approach is to encrypt data at the source before it is placed in a database or at the end-point device before it’s shared. This is when a data-defined approach becomes a game changer and can protect data shared by an application or cloud service.
Now imagine a technology that can operate in the background, invisibly such that all data is encrypted just before leaving your device (any device) en route to either websites, cloud applications but remains encrypted in the receiving database holding your PII or PHI information. If we assume for a moment that the unencrypted data is pure gold, once it is automatically encrypted, it becomes as worthless as a rock as it travels to recipients. At any point when the data resides on intermediate locations such as 3rd party SaaS services, or any database backed application data remains protected. When recipients receive the encrypted data and the user is authorized, it is unencrypted and turned back into its golden state without the recipient having to run separate security software or lookups or ask for passwords from the sender to gain access to the data or communications. The ‘clear’ data is made available within the application or displayed in web browser for the user.
Eliminating the arduous task of data encryption now ensures that all data is protected when shared with others and its security remains in the control of the sender or data owner. When protected data is lost, stolen, abandoned, or forgotten, it remains secure and becomes permanently inaccessible and demonetized once access is removed or retired, ensuring that cybercriminals, non-authorized users and even the occasional alien, only obtain unintelligible data - nothing more than a pile of worthless rocks!

Stolen corporate data is a lucrative business driven by cyber criminals and monetized through ransomware demands or by data breach brokers on the dark web. In fact, loss of data is a cost of doing business. Tragically, Capital One confirmed on July 2019 that they were the target of a major data breach. An enterprising hacker exploited a vulnerability in the cloud infrastructure used by Capital One to hold sensitive data on more than 100 million customers and credit applicants. Capital One claimed the loss would approximately be $100 to $150 million in 2019, that is largely for customer notifications, credit monitoring, technology costs, and legal support. Globally, there are on average four data breaches per day losing approximately 6 million personal records. After all the billions of stolen Personally Identifiable Information (PII), why is this still happening? The truth is that once an attacker gets past the perimeter security, the data is freely available, stolen and then sold to the highest bidder on unscrupulous trading and auction sites.

It has been revealed by the Capital One hacker suspect and the Department of Justice, entrance was possible by exploiting a misconfigured web application firewall that enabled the attacker to run commands and exfiltrate data. What is more interesting is that once past the firewall, nothing stopped access to the data. The suspect claimed to have launched an instance within Capital One’s cloud environment and after attaching the correct security profile, dumped the contents of their MySQL database to a 32TB storage before encrypting it and pulling it out over an OpenVPN session. This means that once past the perimeter security, the data is available in the clear for the taking. But how is this possible given the many database security measures touted by the Database ISVs?
Let us take a closer look at what is available to protect data in most databases. Transparent Data Encryption, or TDE, is designed to protect data-at-rest. In other words, TDE encrypts and decrypts data as it is written or read from the storage connected to the database. Generally speaking, TDE really only protects from physical attacks on the actual storage. Which means, when someone steals the drives holding the data or somehow gets access to the file system managing the storage without TDE, then yes, one can get the data files lock, stock, and barrel. But given the data is in the cloud or in secured datacenters, this is unlikely and rarely if ever occurs these days.
Next is Column or Cell Level Encryption, CLE. CLE has been around for some time and allows the ability to encrypt a full column of data within a database. However, its use is limited due to the impact on the database’s performance. Most databases see a performance loss of 20% to 30% when encrypting a single column of data. Encrypting multiple columns is not recommended as a best practice because it is exponentially worse, therefore almost never deployed.
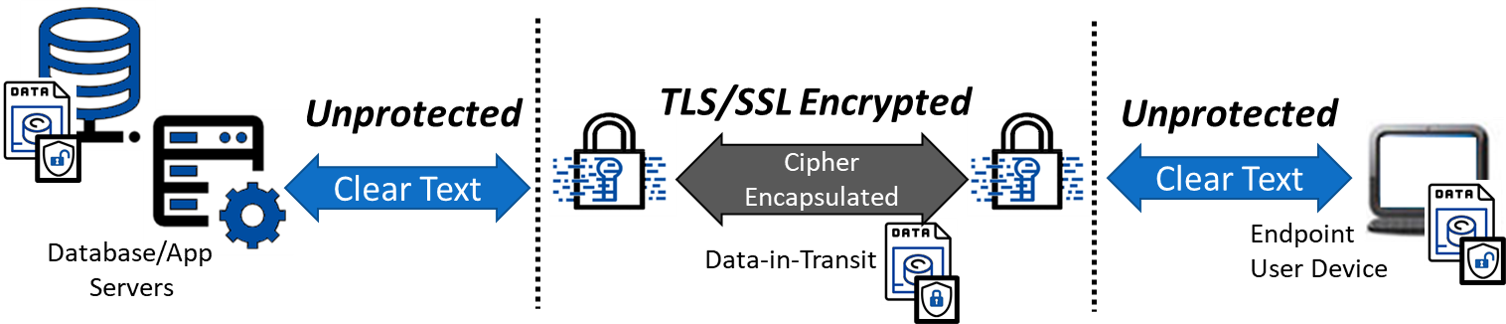
Finally, we have SSL/TLS. If you have ever seen that little gold lock icon in your web browser, then you have experienced the automated use of SSL to protect data-in-flight between the website and your browser. Unfortunately, SSL/TLS is routinely over inflated as having the ability to holistically protect data. Once data arrives in the cloud or on an end-user’s system (laptop, smartphone, or tablet), SSL’s job is done, and the data is decrypted. Continued data protection requires another system or solution to secure it. Therefore, if someone gets past the perimeter security and obtains permission to perform queries on the database, the data will be delivered to the intruder in the clear.
So, what is the solution? Adopt a data-defined approach to cybersecurity which enables demonetization of breached data. The best way to accomplish this, and dare we say to stop large- or small-scale data breaches such as the Capital One event, is to encrypt the data at the source (when users or systems enter data into the front-end application) and keep it encrypted until it's needed by an authorized user. At that time, data can be decrypted for the authorized user. What this means for database driven applications is to encrypt data before it is sent to the database application where it remains encrypted. When done correctly, the database management system has no idea it is operating on encrypted data allowing all the features of searching for records to remain the same. When a breach occurs, the best a cybercriminal can obtain is unintelligible/encrypted data from the database that has no value in the black market.
“Human Error” is a variable in the technology world and one we must anticipate. Protecting data at the source is the last stand against a data breach.

